
ollvm代码混淆
编译器
概念
将高级语言编写的程序转换位目标语言(通常是机器语言)的程序叫做编译器.这个转换的过程叫编译.不同于在执行解释性语言解释器总存在且逐行解释,编译器一次性把整个程序编译成二进制代码从而一般情况运行更快.但是由于解释器可以在不同平台上运作,兼容性,跨平台性更强.
编译器构成
传统的编译器构成常分为三个部分:前端,优化器,后端.编译过程中,前端负责语法分析,将源代码转为其高级形式:抽象语法树(即把源代码的字符串转为内存中有意义的数据);优化器将经过前端处理的中间代码进行优化;后端将优化后的中间代码转换为对应的汇编语言.
主要编译器
GCC
GCC(GNU Compiler Collection,GNU 编译器套装),是一套由 GNU 开发的编程语言编译器。GCC 原名为 GNU C 语言编译器,因为它原本只能处理 C语言。GCC 快速演进,变得可处理 C++、Fortran、Pascal、Objective-C、Java 以及 Ada 等他语言。
LLVM
LLVM (Low Level Virtual Machine,底层虚拟机))提供了与编译器相关的支持,能够进行程序语言的编译期优化、链接优化、在线编译优化、代码生成。简而言之,可以作为多种编译器的后台来使用。
苹果公司一直使用 GCC 作为官方的编译器。GCC 作为一款开源的编译器,一直做得不错,但 Apple 对编译工具会提出更高的要求。原因主要有以下两点:
其一,是 Apple 对 Objective-C 语言(包括后来对 C 语言)新增很多特性,但 GCC 开发者并不买 Apple 的账——不给实现,因此索性后来两者分成两条分支分别开发,这也造成 Apple 的编译器版本远落后于 GCC 的官方版本。
其二,GCC 的代码耦合度太高,很难独立,而且越是后期的版本,代码质量越差,但 Apple 想做的很多功能(比如更好的 IDE 支持),需要模块化的方式来调用 GCC,但 GCC一直不给做。
该编译器的特殊点在于中间表示(IR).这是前端将源代码生成为一种类机器码(各平台不同),并可以由LLVM后端解析的代码.用以扩展解释器的跨平台性.此前,一般是把源代码编译成C代码然后交由对应平台的C编译器编译成二进制文件(因为一般平台都有C编译器).在LLVM中,只需要把源文件编译成IR然后交由LLVM后端直接编译到对应平台.
CLANG
Clang 是 LLVM 的前端,于LLVM的后端组合可以当作另一个编译器,Clang是Apple研发的前端旨在代替GCC的前端
OLLVM
在LLVM基础上,Obfuscator-LLVM项目被研发了出来,通过三种混淆Pass(模块)完善代码的安全性.
- 控制流平坦化
- 指令替换
- 伪造控制流(又叫混淆控制流)
混淆Pass作用于IR,通过混淆IR使后端转换的文件被混淆,使逆向难度增大.
控制流平坦化
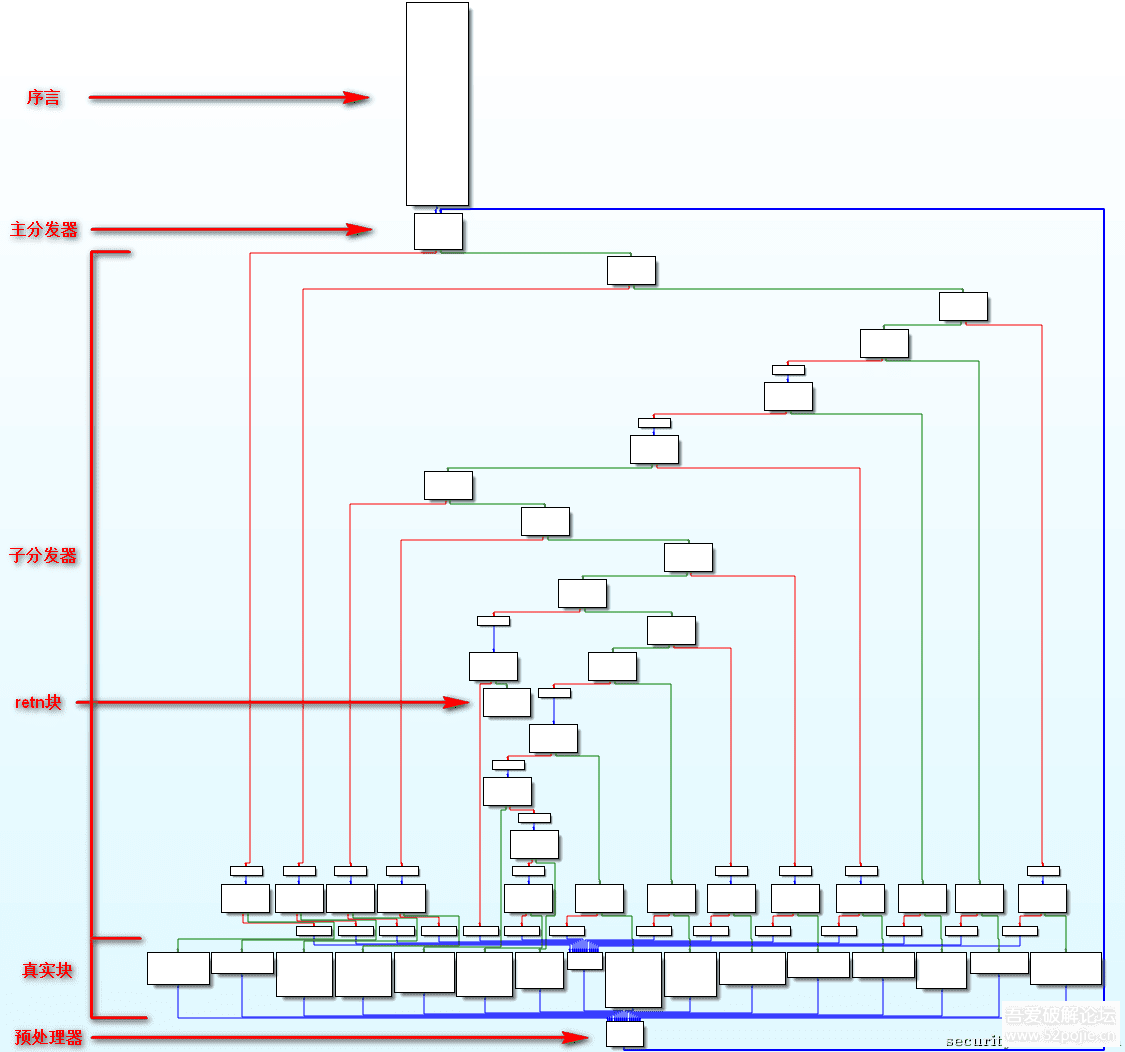
代码本身是真实块和retn块的组合,在进行控制流平坦化之后,程序的流程被分发器控制,所有真实块最后进行对标记的处理然后全部进入预处理器,根据标记的值不同由主分发器分发到副分发器再到真实块,从而混淆了整个执行流程,在反汇编视图中的特征是有很多while循环在后面有switch case语句.(以我的水平来看,控制流平坦化之后几乎不可读)
特征
原始的条件一般会转化为CMOV条件传送指令,根据比较结果设置标记的值
指令替换
用多个表达式替换一个计算表达式
特征
1 | 原式子: |
或者
](https://ask.qcloudimg.com/http-save/yehe-8150619/9571bfa62d17b52593dff42fa4bd9a47.png)
伪造控制流
伪造控制流是在一开始设置一个变量/表达式,这个变量/表达式被称为不透明谓词,并为每一个基本块生成一个垃圾指令块,通过不透明谓词进行跳转到不同位置,但是实际上不会到达垃圾指令块处.
特征图

对于初学者的逆向方法
伪造控制流:见Hex-Rays: 十步杀一人,两步秒OLLVM-BCF(zhihu.com)
控制流平坦化和伪造控制流:见pcy190/deflat: Use angr to deflat the flat control flow. (github.com)
指令替换:见joydo/d810 (github.com)




